本文将从微调的本质、微调的原理、微调的应用三个方面,带您一文搞懂模型微调 Fine-tuning 。
Fine-tuning模型微调
如何利用预训练模型?两种流行方法是迁移学习和微调。迁移学习是一个更广泛的概念,它包括了多种利用预训练模型的方法,而微调是迁移学习中的一种具体实现方式。迁移学习和微调
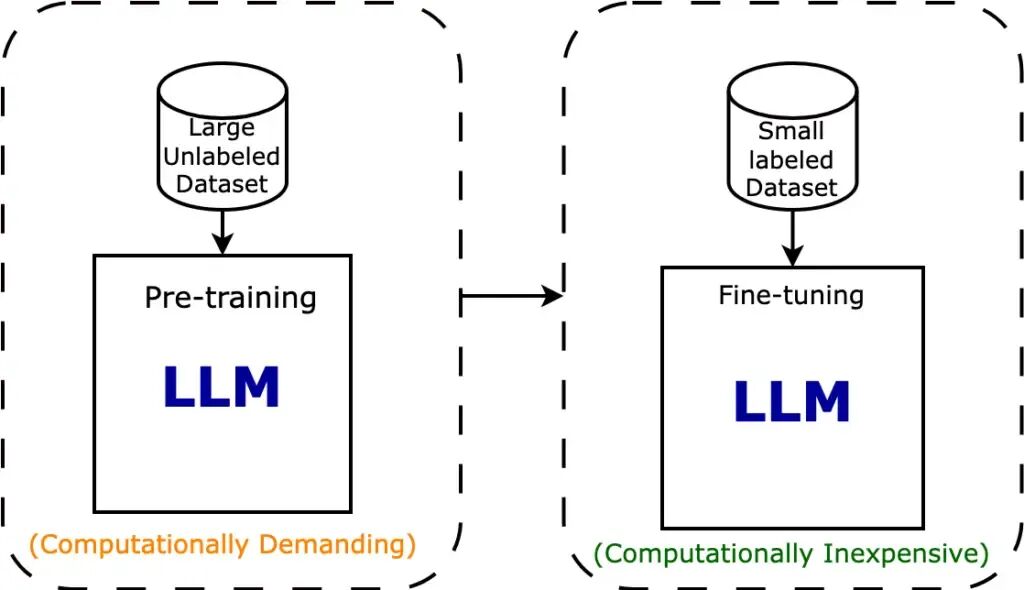
迁移学习(Transfer Learning):使用在大型数据集上预训练的模型作为起点,然后将其应用于新的、相关但可能较小或特定领域的数据集。微调(Fine-tuning):迁移学习的一种具体实现方式,对预训练模型的参数进行进一步的调整和优化,以适应新的任务。为什么需要微调?减少对新数据的需求和降低训练成本。微调的价值:可以帮助我们更好地利用预训练模型的知识,加速和优化新任务的训练过程,同时减少对新数据的需求和降低训练成本。
减少对新数据的需求:从头开始训练一个大型神经网络通常需要大量的数据和计算资源,而在实际应用中,我们可能只有有限的数据集。通过微调预训练模型,我们可以利用预训练模型已经学到的知识,减少对新数据的需求,从而在小数据集上获得更好的性能。
降低训练成本:由于我们只需要调整预训练模型的部分参数,而不是从头开始训练整个模型,因此可以大大减少训练时间和所需的计算资源。这使得微调成为一种高效且经济的解决方案,尤其适用于资源有限的环境。
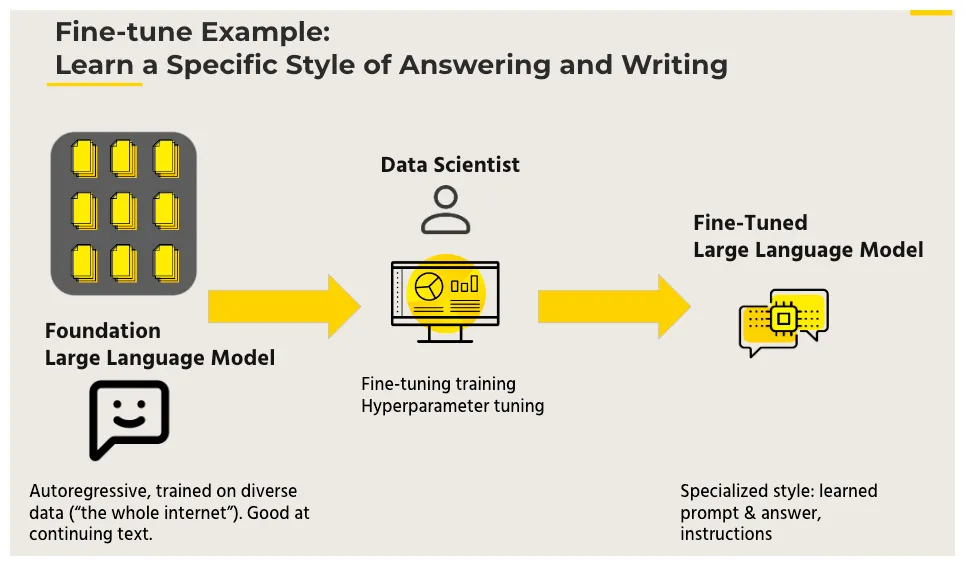
微调的原理:利用已知的网络结构和已知的网络参数,修改output层为我们自己的层,微调最后一层前的若干层的参数。
这样可以有效利用深度神经网络强大的泛化能力,又免去了设计复杂的模型以及耗时良久的训练。因此,Fine-tuning是当数据量不足时的一个比较合适的选择。
参数高效微调PEFT:Parameter-Efficient Fine-Tuning是一种高效的迁移学习技术,它旨在通过最小化微调过程中需要更新的参数数量来降低计算复杂度和提高训练效率。PEFT仅针对部分参数进行微调,从而显著减少了训练时间和成本,尤其适用于数据量有限或计算资源受限的场景。
PEFT包含了多种不同的技术,例如Prefix Tuning、Prompt Tuning、Adapter Tuning和LoRA等,每种技术都有其独特的方法和特点,可以根据具体的任务和模型需求灵活选择。
PEFT的分类
Prompt Tuning
Adapter Tuning
LoRA
CNN的微调:微调的方法包括仅修改最后一层、修改最后几层以及微调整个模型,同时可结合冻结部分层的策略来优化性能。几种微调CNN模型的方法:
方法一:仅修改最后一层(全连接层)
方法二:修改最后几层
方法三:微调整个模型
Transformer的微调:经过预先训练的 Transformer 可以针对众多下游任务快速进行微调,并且通常开箱即用,性能非常好。这主要是因为 Transformer 已经理解了语言,这使得训练可以集中于学习如何进行问答、语言生成、命名实体识别或人们为其模型设定的任何其他目标。Transformer block with adapters:一种有效的参数高效微调技术,它通过在预训练的 Transformer 模型的主干网络中添加额外的适配器(adapters)或残差块,来实现对特定任务的微调。这些适配器通常是可训练的参数,而模型的其他部分则保持固定。
Transformer block with adapters 的微调方法通常包括以下步骤:
加载预训练模型:首先,加载已经在大规模语料库上预训练好的 Transformer 模型。
添加适配器:在模型的主干网络中,为每个 Transformer 层添加适配器。这些适配器可以是简单的线性层或更复杂的结构,具体取决于任务的需求。
初始化适配器参数:为添加的适配器设置初始参数。这些参数通常是随机初始化的,也可以采用其他初始化策略。
进行微调:使用特定任务的数据集对模型进行微调。在微调过程中,仅更新适配器的参数,而保持模型的其他部分不变。
评估性能:在微调完成后,使用验证集评估模型的性能。根据评估结果,可以进一步调整适配器的结构或参数,以优化模型的性能。
































 粤ICP备17114055号
粤ICP备17114055号
